Imagen
It’s no secret that computers have become incredibly good at understanding and responding to human language. But when it comes to generating images from text descriptions, they’re still struggling to create anything that looks remotely realistic. That could all be about to change, thanks to a new text-to-image model called Imagen.
Imagen is an AI system that can create photorealistic images from input text.
Imagen has been designed with two key goals in mind: photorealism and language understanding. To achieve the former, the team relied on diffusion models, which are well known for their ability to generate high-fidelity images. For the latter, they tapped into the power of transformer language models, which have shown impressive results in a variety of tasks such as machine translation and text classification.
The result is a model that can not only generate realistic images from text descriptions but also understand the nuances of language used in those descriptions. For instance, Imagen was able to correctly interpret phrases like “a face with a big smile” and “a close-up of a flower” and generate corresponding images. What’s more, it was also able to handle more complex sentences such as “a man riding a horse on a beach at sunset.”
Ultimately, Imagen represents a major step forward for AI text-to-image generation, and its potential applications are numerous. For instance, it could be used to automatically generate product photography for e-commerce sites or create photo-realistic 3D renderings for architectural visualizations. The possibilities are endless – and we can’t wait to see what Imagen will be able to do next.
How Does Imagen Work?
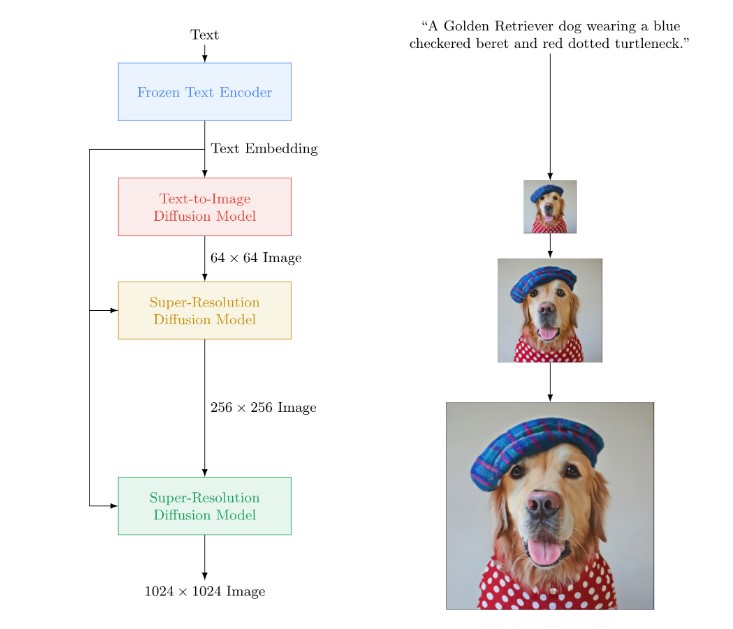
Imagen is a three-stage transformer model that uses text as inputs to generate corresponding images. The caption is passed through a text encoder, which transforms the picture’s semantic information into a number code. The decoded code is then sent to the resolution model that received the decode, which generates a high-resolution picture of the deciphered code.
Despite the incoherence of the text prompts, the Imagen AI can generate reasonably accurate images. This could have significant implications for search engines and other applications where semantically understanding an image is important.
Researchers have found that large language models pre-trained on text-only data are quite effective at encoding text for image synthesis. This discovery could have far-reaching implications for the field of computer vision.
The new technique used in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model.
Without ever training on COCO, Imagen obtains a new state-of-the-art FID score of 7.27 on the COCO dataset. These results suggest that Imagen could be a powerful tool for generating realistic images from textual descriptions.
While Imagen is still in its early stages, the potential applications are numerous. For example, the system could be used to create realistic character models for video games or movies. Or it could be used to generate images of products for marketing purposes. Ultimately, Imagen has the potential to change the way we think about image generation.
Examples of Images Created by Imagen

